
巨屌 自慰 LLM惊现东说念主类脑叶结构并稀有学代码分区,MIT大牛新作战栗学界
裁剪:裁剪部 HYZ巨屌 自慰 【新智元导读】Max Tegmark团队又出神作了!他们发现,LLM中尽然存在东说念主类大脑结构同样的脑叶分区,分为数学/代码、漫笔本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非东说念主类特有,硅基生命也隶属这一法例。 LLM尽然长「脑子」了? 就在刚刚,MIT传说大牛Max Tegmark团队的新作,再次炸翻AI圈。 论文地址:https://arxiv.org/abs/2410.19750 他们发现,LLM学习的成见中,尽然炫夸出令东说念主惊诧的
-

裁剪:裁剪部 HYZ巨屌 自慰
【新智元导读】Max Tegmark团队又出神作了!他们发现,LLM中尽然存在东说念主类大脑结构同样的脑叶分区,分为数学/代码、漫笔本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非东说念主类特有,硅基生命也隶属这一法例。
LLM尽然长「脑子」了?
就在刚刚,MIT传说大牛Max Tegmark团队的新作,再次炸翻AI圈。

论文地址:https://arxiv.org/abs/2410.19750
他们发现,LLM学习的成见中,尽然炫夸出令东说念主惊诧的几何结构——
开头,它们形成一种类似东说念主类大脑的「脑叶」;其次,它们形成了一种「语义晶体」,比初看起来更精准;而况,LLM的成见云更具分形特征,而非圆形。

具体而言,这篇论文探讨了LLM中寥落自编码器(SAE)的特征向量表示的。
Max Tegmark团队的研究亏欠标明,SAE特征所代表的成见六合在多个空间模范上展现出兴致的结构,从语义关系的原子层面到通盘特征空间的大畛域组织。
这就为咱们调治LLM的里面表征和科罚机制,提供了全新的视力。
总之,这个研究真的太过颤动!网友直言:如果LLM和东说念主脑相似,这真的是给东说念主一种不好的猜度……
是以,飘逸的当然法例并不独属于东说念主类,硅基也隶属于这一法例。
这个发现解说了:数学才是一切的基础,而非东说念主类构造。
LLM的三个层面:原子,大脑和星系
团队发现,SAE特征的成见六合在三个层面上都具有兴致的结构:
小模范「原子」
中模范「大脑」
大模范「星系」

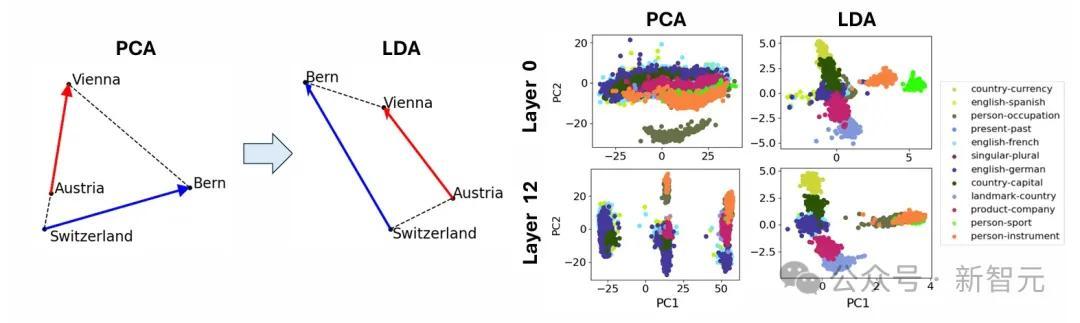
原子级的微不雅结构,包含面为平行四边形或梯形的「晶体」,这是对经典案例的推行(比如「男东说念主-女东说念主-国王-王后」的关系)。
他们发现,当使用线性判别分析(LDA)高效地投影出诸如词长等全局搅扰标的时,这些平行四边形和磋商函数向量的质料会权臣进步。
而类似「大脑」的中间模范结构,则展现出了显着的空间模块化特征,团队将其描画为空间集群和共现集群之间的对都。
比如,数学和代码特征形成了一个「脑叶」,跟神经功能磁共振图像中不雅察到的东说念主类大脑功能分区相似。
团队诓骗多个目的,对这些功能区的空间局部性进行了量化分析,发刻下饱和鄙俗的模范上,共同出现的特征簇在空间上的麇集进度远卓著特征几何立地漫衍情况下的预期值。
而在「星系」的大模范结构上,特征点云并非呈各向同性(各个标的性质疏浚),而是阐扬出特征值幂律漫衍,中间层的斜率最抖。
而聚类熵也在中间层周围达到峰值!
看完这个研究,有网友给出了这么的评价——
「如果这项研究出自Max Tegmark以外的任何东说念主,我都会合计他是疯子。但Tegmark是咱们这个期间最优秀的科学家之一。当我说果断是一种数学模式、一种物资情景时,我援用的是他。」
LLM学习成见中,惊东说念主的三层几何结构
客岁,AI圈在调治LLM若何职责上取得了残害,寥落自编码器在其激活空间中,发现了大都不错解释为成见的点(「特征」)。
寥落自编码器看成在无监督情况下发现可解释谈话模子特征的顺次,受到了好多温雅,而检验SAE特征结构的职责则较少。
这类SAE点云最近照旧公开,MIT团队认为,是时候研究它们在不同模范上的结构了。
「原子」模范:晶体结构
在SAE特征的点云中,研究者试图寻找一种称之为「晶体结构」的东西。
这是指反馈成见之间语义关系的几何结构,一个经典的例子等于(a, b, c, d)=(男东说念主,女东说念主,国王,女王)。
它们形成了一个近似的平行四边形,其中b−a≈d−c。
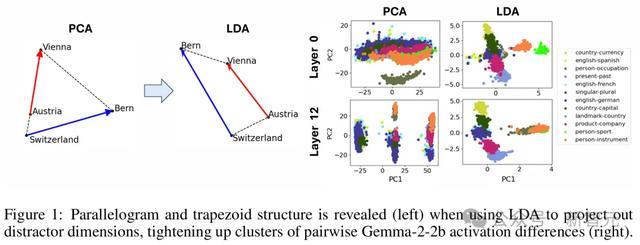
这不错解释为,两个函数向量b−a和c−a分别将男性实体变为女性,将实体变为皇室。
研究者还搜索了唯有一双平行边b−a ∝ d−c的梯形(对应于仅一个函数向量)。
图1(右)即为这么的一个例子:(a, b, c, d)=(奥地利,维也纳,瑞士,伯尔尼),其中函数向量不错解释为将国度映射到其都门。
研究者通过接洽通盘成对的差向量并对其进行聚类来搜索晶体,这应该会产生与每个函数向量相对应的一个簇。
簇中的任何一双差向量,应该组成梯形或平行四边形,这取决于在聚类之前差向量是否被归一化(或者不错等效于,是否通过欧几里得距离或余弦相似度,来量化了两个差向量之间的相似性)。
率先搜索SAE晶体时,研究者发现的大多是噪声。
为什么会出现这种情况?
为了拜访原因,研究者将注重力聚会在了在第0层(token镶嵌)和第1层,在这些层中,许多SAE特征与单个词相对应。
然后,他们研究了Gemma2 2B模子中来自数据集的残差流激活,这些激活对应于先前通告的词->词函数向量,于是搞明白了这个问题。
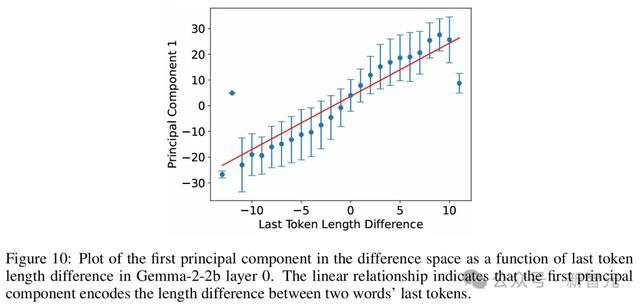
如图1所示,晶体四重向量时常远非平行四边形或梯形。
这与多篇论文指出的情况一致,即(男,女,国王,王后)并不是一个准确的平行四边形。
之是以会有这种快意,是因为存在一种所谓的「搅扰特征」。
比如,图1(右)中的横轴主要对应于单词长度。
这在语义上是不磋商的,而况对梯形(左)酿成了严重残害,因为「Switzerland」要比其他的词长好多。
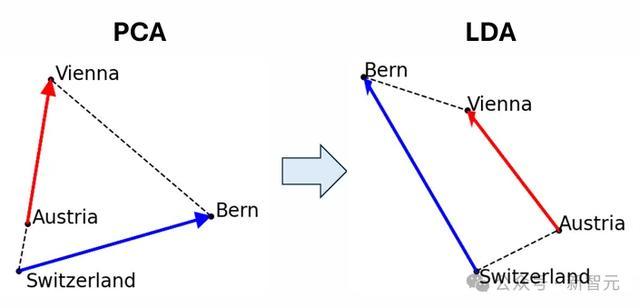
为了排斥这些语义上无关的搅扰向量,研究者但愿将数据投影到与这些搅扰向量正交的低维子空间上。
对于数据集,他们使用了线性判别分析(LDA)来罢了这少许。LDA将数据投影到信号噪声比特征模式上,其中「信号」和「噪声」分别界说为簇间变化和簇内变化的协方差矩阵。
这种仿佛权臣改善了簇和梯形/平行四边形的质料,凸显出搅扰特征可能隐蔽了现存的晶体结构。
「大脑」模范:中等模范的模块结构
接下来,咱们到了论文最精彩的处所。
在这一部分,研究者们削弱了视角,试图寻找更大畛域的结构。
他们研究了功能相似的SAE特征组(这些特征组倾向于一齐激活),念念望望它们是否在几何上亦然相似的,是否会在激活空间中形成「脑叶」。
在动物的大脑中,这种功能组等于家喻户晓的神经元所在的三维空间中的簇。
举例,布罗卡区触及谈话生成,听觉皮层科罚声息,杏仁核主要科罚心思。
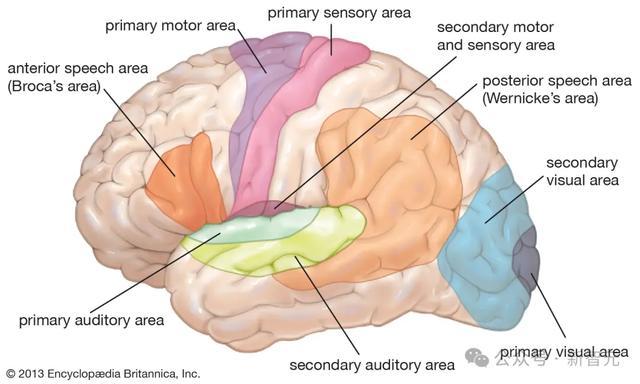
研究者相配酷好,是否不错在SAE特征空间中找到类似的功能模块呢?
他们测试了多种顺次,来自动发现这类功能性「脑叶」,并量化它们是否是空间模块化的。
他们将脑叶分区界说为点云的一个k子集的分离,这种分区的接洽不使用位置信息,相背,他们是基于它们在功能上的关联性来识别这些脑叶分区的。
具体来说,这些脑叶在吞并文档内倾向于一齐激活。
为了自动识别功能脑叶,研究者开头接洽了SAE特征共现的直方图。
他们使用Gemma2 2B模子科罚了来自The Pile的文档。
研究者发现,在第12层的残差流SAE具有16k个特征,平均L0为41。
他们纪录了这个SAE被激活的特征(如果某特征的荫藏激活值> 1,则将其视为被激活)。
如果两个特征在吞并个256个token的块内同期激活,则它们被视为共现。
此长度提供了一种鄙俗的「技术分辨率」,使他们能够发现倾向于在吞并文档中共同激活的token,而不仅限于吞并token。
研究者使用了最大长度为1024的凹凸文,而况每个文档只使用一个这么的凹凸文,这就使他们在The Pile的每个文档中最多有4个块(和直方图更新)。
他们在5万个文档上钩算了直方图。
基于此直方图,他们根据SAE特征的共现统计,接洽了每对特征之间的亲和分数,并对得到的亲和矩阵进行了谱聚类。
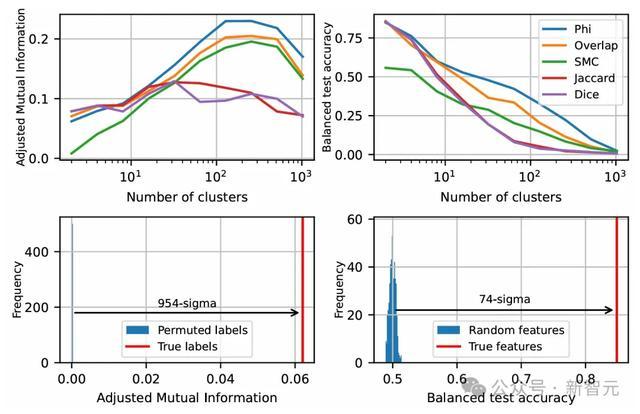
研究者尝试了以下基于共现的亲和度接洽顺次:浅显匹配总计、Jaccard相似度、Dice总计、类似总计和Phi总计,这些都不错仅通过共现直方图接洽得出。

研究者们正本假设,功能上相似的点(即常见的共现SAE特征)在激活空间中应该是均匀漫衍的,不会阐扬出空间模块性。
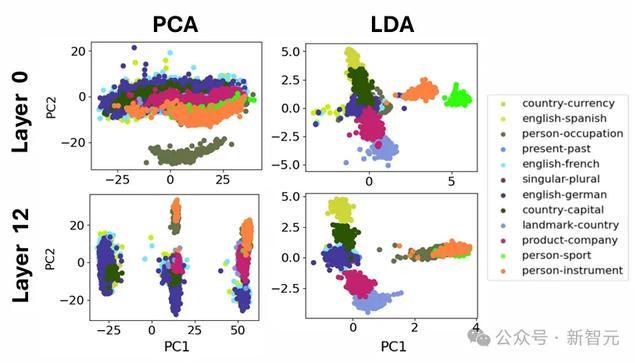
然而,出乎他们预念念,图2炫夸出:脑叶在视觉上呈现出特等聚会的空间漫衍!

在SAE点云中识别出的特征倾向于在文档中一齐激活,同期也在几何上共同定位于功能「脑叶」中,左侧的2脑叶分离将点云大约分为两部分,分别在代码/数学文档和英文文档上激活。右侧的3脑叶分离主要将英文脑叶细分为一个包含神圣讯息和对话的部分,以及一个主要包含长篇科学论文的部分
为了量化其统计权臣性,研究者使用了两种顺次来根除原假设:
1. 固然不错基于特征是否同期出现进行聚类,但也不错基于SAE特征解码向量的余弦相似度来进行谱聚类。
他们开头使用了余弦相似度对SAE特征进行聚类,然后使用共现对特征进行聚类,之后接洽这两组标签之间的相互信息。
在某种兴致上,这径直揣度了通过了解功能结构不错赢得若干对于几何结构的信息。
2. 另一个顺次等于教师模子,通过几何信息展望特征所属的功能脑叶。
为此,研究者将基于共现聚类得到的脑叶标签集看成宗旨,使用逻辑回来模子径直根据点的位置展望这些标签,并使用80-20的教师-测试集分离,通告该分类器的均衡测试准确率。
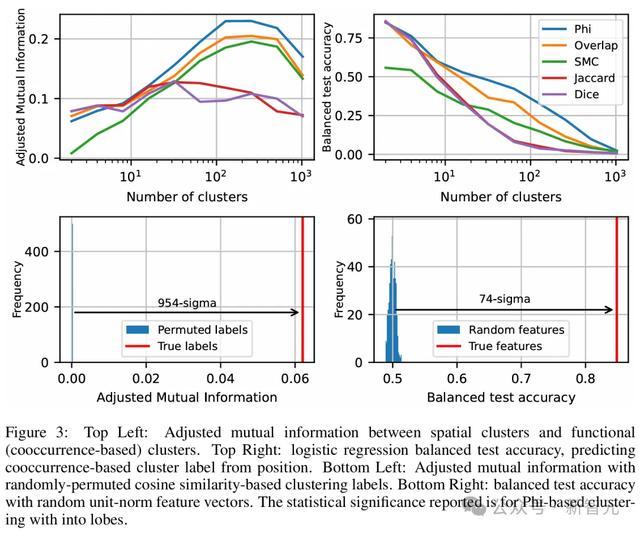
左上:空间聚类与功能聚类之间的诊治互信息。右上:逻辑回来的均衡测试准确率,用位置展望基于共现的聚类标签。左下:立地置换余弦相似度聚类标签后的诊治互信息。右下:立地单元范数特征向量的均衡测试准确率。通告的统计权臣性基于Phi总计的脑叶聚类
图3炫夸,对于两种度量顺次,Phi总计成果最好,提供了功能脑叶与特征几何时事之间的最好对应关系。
为了解说其统计权臣性,研究者立地打乱了基于余弦相似度聚类的簇标签,并测量了诊治后的相互信息。
同期,他们使用立地高斯漫衍,对SAE特征解码标的再行启动化并归一化,然后教师逻辑回来模子从这些特征标的展望功能脑叶。
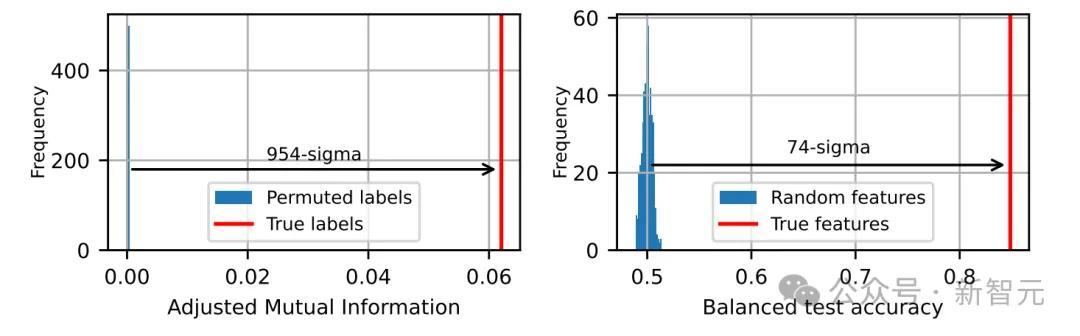
图3(下)炫夸,两项测试都以极高的权臣性根除了零假设,分别达到了954和74个模范差,这就明确标明:研究者所不雅察到的脑叶是真确的,而非统计就怕!
为了评估每个脑叶的专长,他们将The Pile数据聚会的1万份文档输入了Gemma2 2B模子,并再次纪录了第12层中每256个token块内触发的SAE特征。
对于每个token块,他们都纪录了具有最高特征触发比例的脑叶。
The Pile中的每个文档都带着称号,指定该文档属于语料库的哪个子集。对于每种文档类型,针对该类型文档中每个256 token块,他们都会纪录哪一个脑叶具有最高的SAE特征触发比例。
逾越数千份文档后,不错检验每种文档类型中,哪个脑叶的激活比例最高的直方图。
在图4中,研究者展示了使用Phi总计看成共现度量接洽的三个脑叶亏欠,这组成了图2中脑叶标志的基础。

每个脑叶都具有最高比例的激活特征凹凸文分数。脑叶2时常在代码和数学文档上不行比例地被激活,脑叶0在包含文本(聊天纪录、会议纪录)的文档上激活更多,脑叶1在科学论文上激活更多
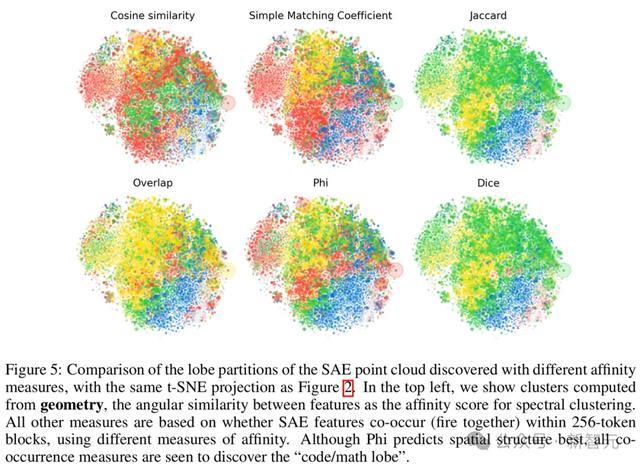
图5对比了五种不同共现度量的成果。尽管Phi总计最好,但五种度量顺次均能够识别出「代码/数学脑叶」。
「星系」模范:「大畛域」点云结构
临了一种,让咱们进一步拉远视角,望望大模子在「星系」模范结构中,点云的形貌。
主若是研究其全体时事、聚类,类似于天文体家研究硬核系时事和子结构的样子。

接下来,研究东说念主员试图去根除一个浅显的零假设(null hypothesis):点云仅仅从各向同性多元高斯漫衍中采样的。
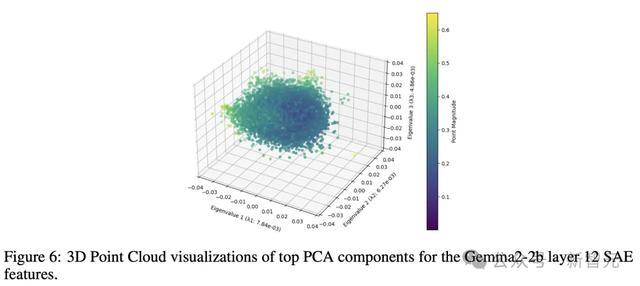
如图6直不雅地标明,即使在其前三个主要要素中,点云漫衍也不十足是圆形的,某些主轴略宽于其他轴,类似东说念主脑的时事。
时事分析
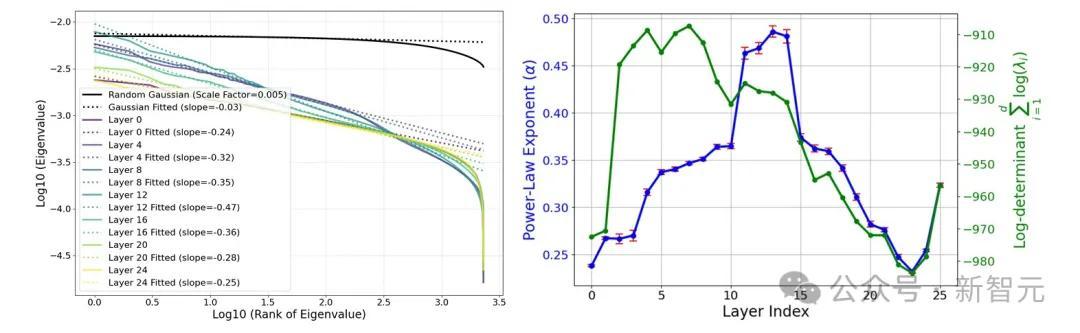
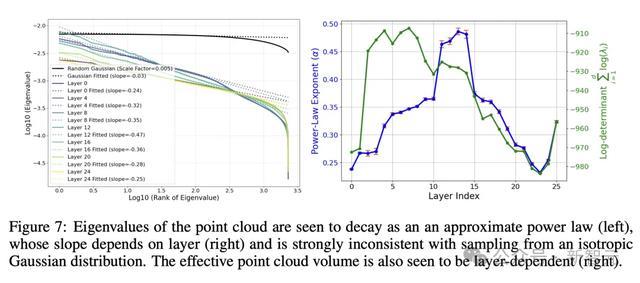
图7(左)通过点云协方差矩阵的特征值排序,来量化这一快意。
它揭示出,这些特征值并非是恒定的,而是呈现出幂律衰减。
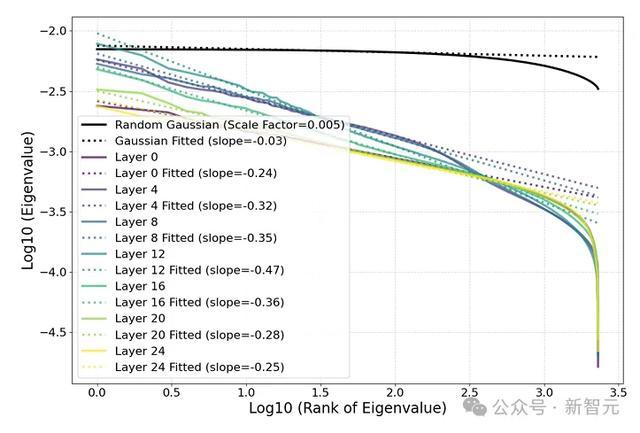
为了查考这个令东说念主惊诧的幂律是否权臣,图中将其与从各向同性高斯漫衍中抽取的点云的相应特征值谱进行比较。
亏欠炫夸,后者愈加平摊,而况与分析展望一致:
从多元高斯漫衍中抽取的N个立地向量的协方差矩阵死守Wishart漫衍
这少许,照旧在立地矩阵表面中,得到了充分的研究。
由于,最小特征值的急剧下落是由有限数据引起的,并在N趋于无限大时隐藏,研究东说念主员在后续分析中,将点云降维到其100个主要素。
换句话说,点云的时事像一个「分形黄瓜」,其在相接维度上的宽度像幂律同样下落。
研究东说念主员发现,与SAE特征比拟,激活值的幂律特征显着较弱。改日,进一步研究其成因,也将是一个兴致的标的。
图7(右)炫夸了,上述幂律的斜率若何随LLM层数变化,这是通过对100个最大特征进行线性回来接洽得到的。
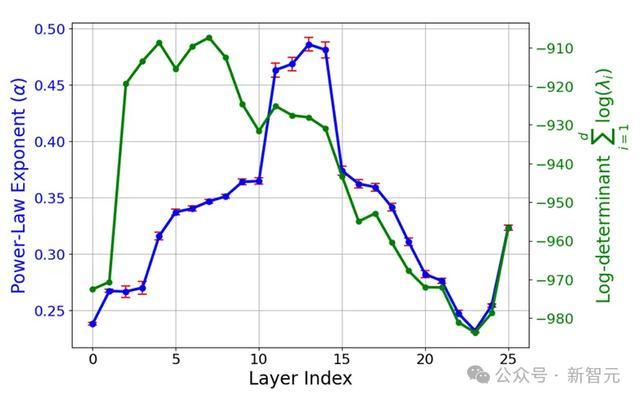
研究东说念主员不雅察到一个知道的模式:
中间层具有最陡的幂律斜率(第12层的斜率为-0.47),而早期和后期层(如第0层和第24层)的斜率较为邋遢(分别为-0.24和-0.25)。
这可能示意了,中间层充任了一个瓶颈,将信息压缩到更少的主要素中,冒昧是为了更有用表示高层空洞成见。
图7(右)还在对数模范上,展示了有用云体积(协方差矩阵的行列式)若何随层数变化。
聚类分析
一般来说,星系或微不雅粒子的聚类,时常通过幂谱或磋商函数来量化。
对于研究中高维数据来说,这种量化变得很复杂。
因为底层密度会跟着半径变化,而对于高维高斯漫衍,密度锐利聚会在相对较薄的球壳周围。
由此,研究东说念主员聘用通过揣摸点云,假设采样的漫衍的「熵」来量化聚类。
他们使用k-NN顺次来揣摸熵H,接洽如下:
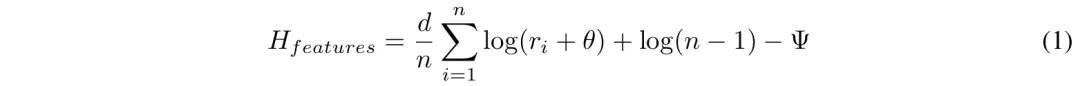
其中ri是点i到第k个最隔邻的距离,d是点云的维度;n是点的数目;
常数Ψ是k-NN揣摸中的digamma项。看成基线,高斯熵代表了给定协方差矩阵的最大可能熵。
对于具有疏浚协方差矩阵的高斯漫衍,熵的接洽顺次如下:
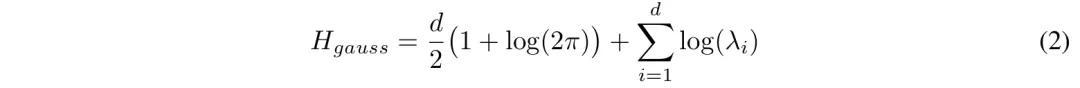
其中λi是协方差矩阵的特征值。
研究东说念主员界说聚类熵,或「负熵」,为Hgauss − H,即熵比其最大允许值低若干。
图8炫夸了不同层的揣摸聚类熵。不错看到,SAE点云在中间层锐利麇集。
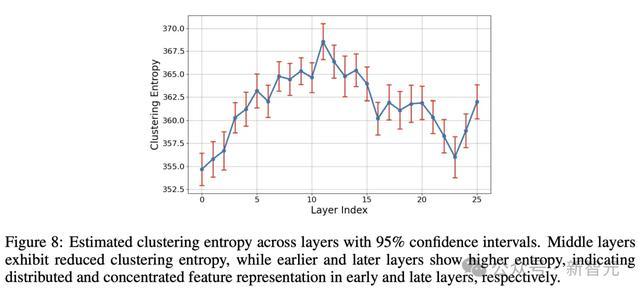
在改日研究中,研究这些变化是否主要取决于不同层中晶体或叶状结构的权臣性,或者是否有十足不同的发源,将会是一个兴致的标的。
破解LLM运作机制黑箱,东说念主类再近一步
一言以蔽之,MIT团队这项最新研究中,揭示了SAE点云成见空间具有三层兴致的结构:
原子模范的晶体结构;大脑模范的模块结构;星系模范的点云结构。
正如网友所言,亲眼目击了东说念主类硅基孩子在我眼前成长,既令东说念主敬畏又令东说念主畏怯。

Max Tegmark出品,必属杰作。
此前就有东说念主发现,仅鄙人一个token展望上教师的序列模子中,存在线性表征的类似左证。
23年2月,哈佛、MIT的研究东说念主员发表了一项新研究Othello-GPT,在浅显的棋盘游戏中考据了里面表征的有用性。
在莫得任何奥赛罗规章先验常识的情况下,研究东说念主员发现模子能够以相配高的准确率展望出正当的移动操作,捕捉棋盘的情景。他们认为谈话模子的里面如实修复了一个全国模子,而不仅仅单纯的顾虑或是统计,不外其智商来源还不明晰。
吴恩达对该研究表示了高度招供。

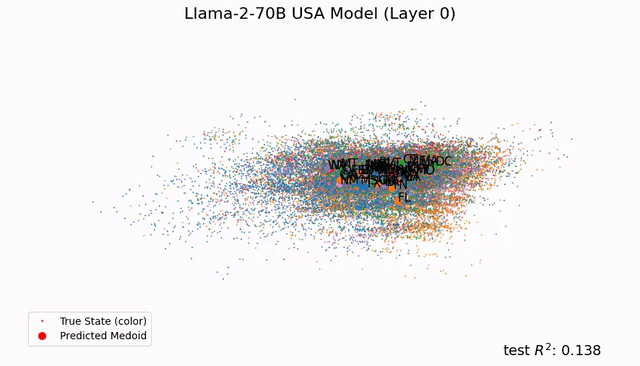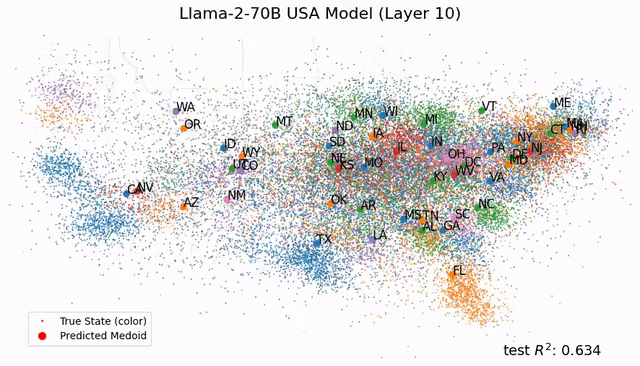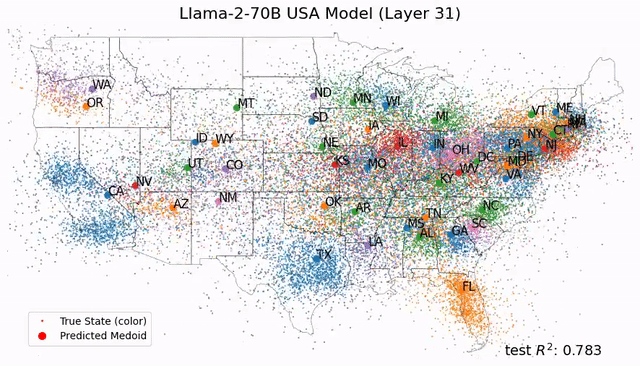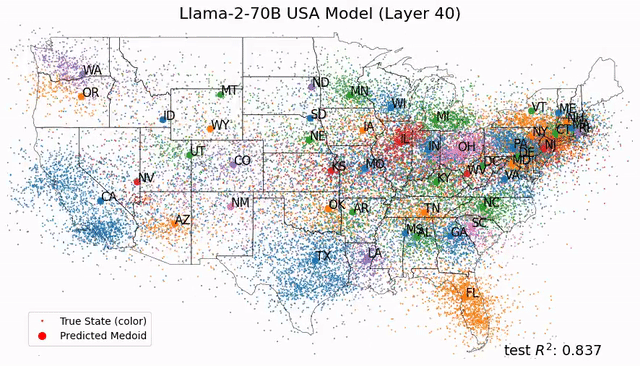
受此启发,Max Tegmark团队发现,Llama-2-70B竟然能够描述出研究东说念主员真确全国的笔墨舆图,还能展望每个处所真确的纬度和经度;而在技术表征上,模子见效展望了名东说念主的升天年份、歌曲电影竹素的发布日历和新闻的出书日历。
总之,这项研究在LLM中发现了「经度神经元」,在学界引起了宏大反响。
茄子香蕉视频丝瓜在线观看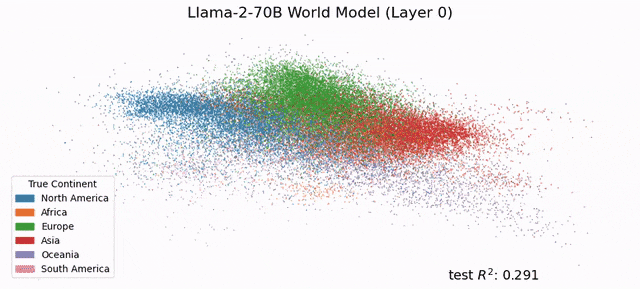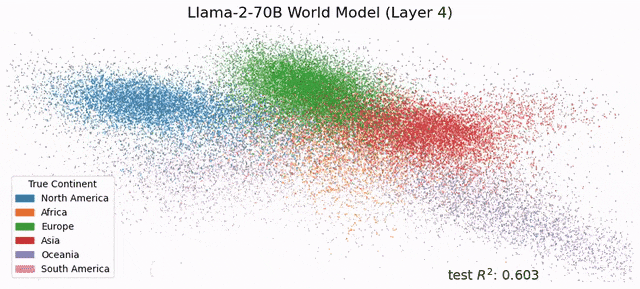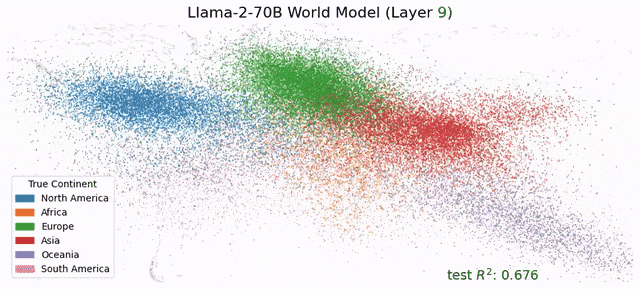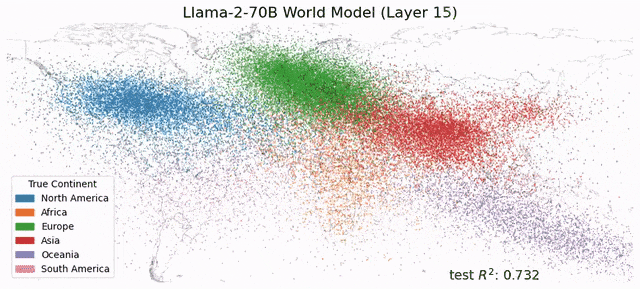
如今,Tegmark团队又再进一步巨屌 自慰,帮咱们从更微不雅的角度解析LLM的大脑。东说念主类离解释LLM运作机制的黑箱,又近了一步。